1. Thanos là gì trong hệ sinh thái Prometheus?
Trong Prometheus, Thanos là một bộ công cụ mở rộng giúp:
- Kết nối nhiều Prometheus lại với nhau.
- Lưu trữ dữ liệu giám sát dài hạn.
- Đảm bảo hệ thống vẫn hoạt động khi một Prometheus bị lỗi (HA).
- Cho phép truy vấn dữ liệu tập trung (global query) trên nhiều Prometheus.
Ví dụ tên gọi “Thanos” lấy cảm hứng từ nhân vật trong Marvel – mạnh mẽ, kiểm soát và quản lý toàn cục – tương tự như cách Thanos trong Prometheus giúp bạn kiểm soát toàn bộ hệ thống giám sát.
Tại sao cần dùng Thanos thay vì chỉ dùng Prometheus?
Prometheus rất tốt cho giám sát hệ thống đơn cụm, nhưng nó có các giới hạn:
- Không lưu trữ dữ liệu lâu dài.
- Không hỗ trợ high availability một cách bản địa.
- Không dễ dàng truy vấn từ nhiều cụm Prometheus khác nhau.
Thanos ra đời để giải quyết tất cả những vấn đề này:
- Hỗ trợ HA (High Availability).
- Lưu trữ dài hạn trên S3/Object Storage.
- Truy vấn dữ liệu toàn cục từ nhiều cụm.
- Hiển thị một góc nhìn toàn hệ thống từ nhiều Prometheus.
2. Kiến trúc và các thành phần chính của Thanos
2.1. Kiến trúc tổng thể
Giải pháp được triển khai theo kiến trúc master-slave:
Cụm master:
- Là trung tâm quản lý.
- Triển khai full
kube-prometheus-stack(Prometheus Operator, Grafana, Alertmanager, Node Exporter…). - Triển khai các service của Thanos:
sidecar,querier,store gateway,compactor.
Cụm slave:
- Chạy các ứng dụng thực tế.
- Chỉ cần Prometheus + Thanos Sidecar (không cần Grafana, Querier, Store, Compactor).
- Prometheus ở đây vẫn có nhiệm vụ scrape metrics, gửi sang Thanos Sidecar, sau đó upload lên Object Storage.
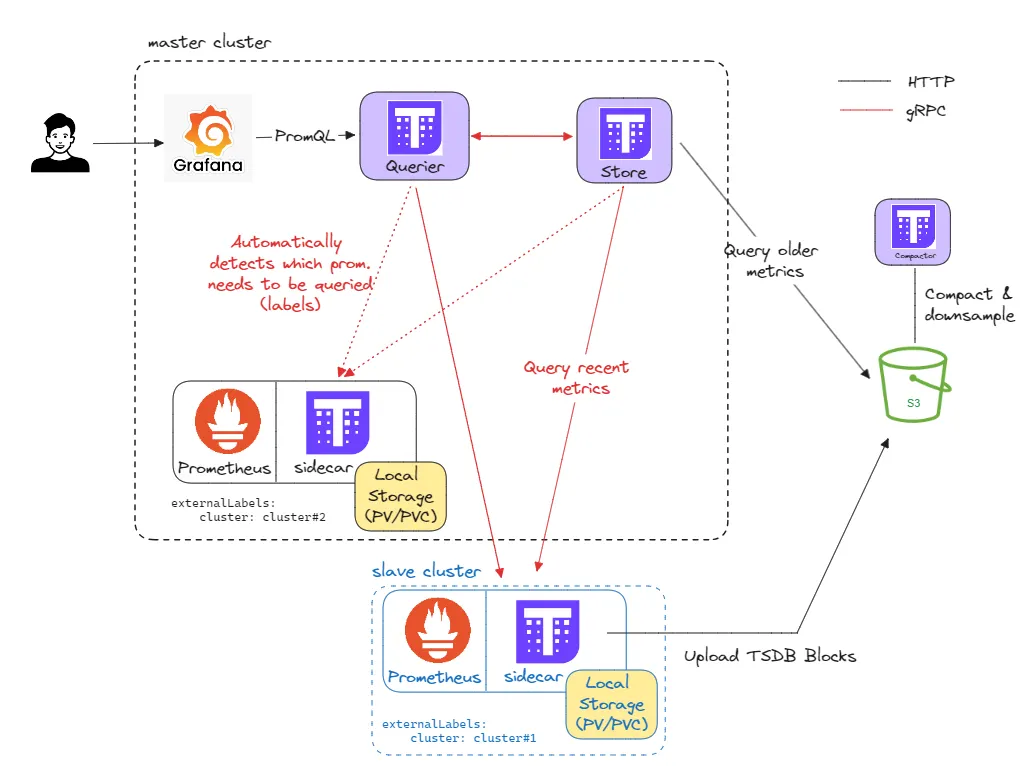
2.2. Các thành phần
Prometheus Instances (Cài đặt dạng HA)
- Có nhiều Prometheus cùng scrape (thu thập) dữ liệu từ một mục tiêu giống nhau.
- Ví dụ:
prometheus-0vàprometheus-1. - Cùng cấu hình → nếu một node chết thì node còn lại vẫn đảm bảo dữ liệu không bị mất.
Thanos Sidecar
Thanos Sidecar là thành phần chạy kèm Prometheus, có 2 chức năng:
- Gửi dữ liệu realtime tới Thanos Querier để truy vấn tức thì.
- Định kỳ đẩy dữ liệu lên object storage (như S3, MinIO…)
Cổng mặc định:
10901: gRPC (Query sẽ dùng cổng này).10902: HTTP (upload lên S3/Object Storage).
Prometheus cần có Persistent Volume lưu tạm dữ liệu khoảng 6 giờ (nếu crash trong 2h giữa các lần upload thì không mất dữ liệu).
Object Storage
- Là nơi lưu trữ dữ liệu dài hạn.
- Hỗ trợ các dịch vụ cloud như: AWS S3, Google Cloud Storage, Azure Blob…
- Cho phép bạn truy xuất dữ liệu cũ kể cả khi Prometheus gốc đã mất dữ liệu.
Thanos Querier
- Là trung tâm để truy vấn dữ liệu từ nhiều Prometheus.
- Tập hợp dữ liệu từ các sidecar và từ object storage.
- Tự động deduplicate dữ liệu trùng lặp (khi có nhiều Prometheus thu thập cùng một dữ liệu).
Thanos Store Gateway
- Hợp nhất các block dữ liệu nhỏ thành block lớn để truy vấn nhanh hơn.
- Tạo ra các phiên bản downsample (dữ liệu thưa hơn) cho việc truy vấn dài hạn.
- Có thể chạy như batch job hoặc service liên tục.
Lưu ý:
- Chỉ Compactor có quyền xóa dữ liệu khỏi Object Store.
- Cần 100–300 GB local disk để hoạt động hiệu quả.
Thanos Compactor
- Nén, hợp nhất và loại bỏ trùng lặp trong các TSDB block trong object storage.
- Tối ưu hóa dung lượng lưu trữ và tăng hiệu năng truy vấn.
Thanos Ruler (Tùy chọn)
- Cho phép chạy các recording rules và alerting rules không phải chỉ trên 1 Prometheus, mà trên toàn bộ dữ liệu toàn cục của hệ thống Thanos.
- Thích hợp cho cảnh báo tập trung trên nhiều cụm Prometheus.
3. Các tính năng HA (High Availability) của Thanos
- Deduplication: Loại bỏ dữ liệu trùng bằng cách nhận diện nhãn (label)
replica. - Redundancy: Có nhiều Prometheus đảm bảo không mất dữ liệu khi một node hỏng.
- Global Aggregation: Truy vấn dữ liệu tổng hợp từ nhiều nguồn.
- Durability: Lưu dữ liệu trên object storage an toàn, không phụ thuộc ổ cứng local
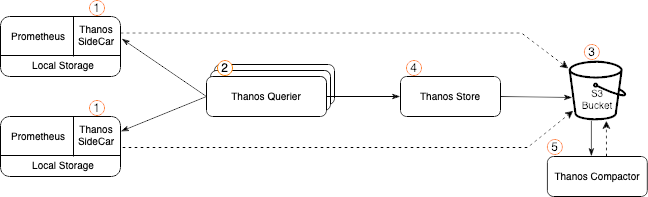
4. Luồng hoạt động
- Prometheus scrape metrics từ các ứng dụng.
- Thanos Sidecar lưu metrics lên S3.
- Grafana gửi query đến Querier.
- Querier lấy dữ liệu từ:
- Sidecar (real-time ≤ 2h)
- Store Gateway (history từ S3)
- Compactor tối ưu hóa các block trong S3.
5. Hướng dẫn triển khai
Yêu cầu trước khi bắt đầu
- Đã có cụm Kubernetes (EKS) sẵn.
- Đã cài Helm.
- Namespace
monitoringđã được tạo:kubectl create ns monitoring - Sử dụng các dịch vụ AWS: EFS (lưu trữ PV), S3 (lưu trữ dài hạn), EKS (K8s) và Load Balancer (truy cập bên ngoài).
Tạo EFS và Access Point
File 1: ap-prometheus-server.json
{
"ClientToken": "prometheus-server-001",
"Tags": [
{
"Key": "Name",
"Value": "Prometheus Server"
}
],
"FileSystemId": "fs-071e026c105d0bc8e",
"PosixUser": {
"Uid": 500,
"Gid": 500,
"SecondaryGids": [2000]
},
"RootDirectory": {
"Path": "/prometheus/server",
"CreationInfo": {
"OwnerUid": 500,
"OwnerGid": 500,
"Permissions": "0755"
}
}
}
File 2: ap-alertmanager.json
{
"ClientToken": "alertmanager-001",
"Tags": [
{
"Key": "Name",
"Value": "Prometheus Alert Manager"
}
],
"FileSystemId": "fs-071e026c105d0bc8e",
"PosixUser": {
"Uid": 501,
"Gid": 501,
"SecondaryGids": [2000]
},
"RootDirectory": {
"Path": "/prometheus/alertmanager",
"CreationInfo": {
"OwnerUid": 501,
"OwnerGid": 501,
"Permissions": "0755"
}
}
}
File 3: ap-grafana.json
{
"ClientToken": "grafana-001",
"Tags": [
{
"Key": "Name",
"Value": "Grafana Server"
}
],
"FileSystemId": "fs-071e026c105d0bc8e",
"PosixUser": {
"Uid": 472,
"Gid": 472,
"SecondaryGids": [2000]
},
"RootDirectory": {
"Path": "/grafana",
"CreationInfo": {
"OwnerUid": 472,
"OwnerGid": 472,
"Permissions": "0755"
}
}
}
Tạo Access Point
aws efs create-access-point --cli-input-json file://ap-prometheus-server.json
aws efs create-access-point --cli-input-json file://ap-alertmanager.json
aws efs create-access-point --cli-input-json file://ap-grafana.json
Tạo StorageClass và PersistentVolume
File: efs-sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: efs-sc
provisioner: efs.csi.aws.com
parameters:
provisioningMode: efs-ap
fileSystemId: fs-071e026c105d0bc8e
directoryPerms: "700"
kubectl apply -f efs-sc.yaml
File: pv-server.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-server
spec:
capacity:
storage: 8Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
csi:
driver: efs.csi.aws.com
volumeHandle: fs-071e026c105d0bc8e::fsap-0b18bb9627fac04c1
File: pv-alertmanager.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: alertmanager-pv
spec:
capacity:
storage: 2Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
claimRef:
namespace: prometheus
name: storage-prometheus-alertmanager-0
csi:
driver: efs.csi.aws.com
volumeHandle: fs-071e026c105d0bc8e::fsap-07e39dff2ec748386
File: pv-grafana.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-server
spec:
capacity:
storage: 8Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
csi:
driver: efs.csi.aws.com
volumeHandle: fs-071e026c105d0bc8e::fsap-0b735362b8eeb1ebe
kubectl apply -f pv-server.yml
kubectl apply -f pv-alertmanager.yml
kubectl apply -f pv-grafana.yml
azureadmin@EKS:~$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
alertmanager-pv 2Gi RWO Retain Available prometheus/storage-prometheus-alertmanager-0 efs-sc <unset> 4m13s
grafana-server 8Gi RWO Retain Available efs-sc <unset> 7s
prometheus-server 8Gi RWO Retain Available efs-sc <unset> 4m20s
Tạo S3 Bucket và Cấp Quyền IAM
a. Tạo bucket ở cùng region với cluster
b. Gán quyền truy cập S3 (IAM Policy)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::<bucket>",
"arn:aws:s3:::<bucket>/*"
]
}
]
}
Cấu hình OIDC + EFS CSI Driver
oidc_id=$(aws eks describe-cluster --name eks --query "cluster.identity.oidc.issuer" --output text | cut -d '/' -f 5)
aws iam list-open-id-connect-providers | grep $oidc_id | cut -d "/" -f4
eksctl utils associate-iam-oidc-provider --cluster eks --approve
Tạo IAM Role cho driver:
eksctl create iamserviceaccount \\
--name efs-csi-controller-sa \\
--namespace kube-system \\
--cluster eks \\
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEFSCSIDriverPolicy \\
--approve \\
--role-only \\
--role-name AmazonEKS_EFS_CSI_DriverRole
eksctl create addon \\
--name aws-efs-csi-driver \\
--cluster eks \\
--service-account-role-arn arn:aws:iam::602320714312:role/AmazonEKS_EFS_CSI_DriverRole \\
--force
Cài đặt kube-prometheus-stack (có Thanos Sidecar)
Cấu hình Helm Chart
helm search repo prometheus-community/kube-prometheus-stack --versions
helm repo add prometheus-community <https://prometheus-community.github.io/helm-charts>
helm repo update
helm show values prometheus-community/kube-prometheus-stack --version "75.15.1" > values.yaml
kubectl create namespace monitoring
Tạo Secret chứa cấu hình truy cập S3:
type: S3
config:
bucket: "thanos-metrics-bucket-eks"
endpoint: "s3.amazonaws.com"
access_key: "AKIAYYPI4XJEPOYLK2HK"
secret_key: "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"
region: "ap-southeast-1"
kubectl -n monitoring create secret generic thanos-storage-config --from-file=thanos-storage-config.yaml=thanos-storage-config.yaml
kubectl get secrets -n monitoring
File values.yaml:
https://github.com/ttnguyenblog/thanos.git
Script cài đặt
helm upgrade --install monitoring prometheus-community/kube-prometheus-stack \\
--namespace monitoring \\
--values values.yaml \\
--version "75.15.1"
azureadmin@EKS:~$ kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-monitoring-kube-prometheus-alertmanager-0 2/2 Running 0 108s
pod/monitoring-grafana-7d7c695546-6kl74 3/3 Running 0 110s
pod/monitoring-kube-prometheus-operator-6cd8f7b5cc-zh25q 1/1 Running 0 110s
pod/monitoring-kube-state-metrics-585b45df98-jfxz2 1/1 Running 0 110s
pod/monitoring-prometheus-node-exporter-5r629 1/1 Running 0 110s
pod/monitoring-prometheus-node-exporter-9vrvs 1/1 Running 0 110s
pod/prometheus-monitoring-kube-prometheus-prometheus-0 3/3 Running 0 107s
pod/prometheus-monitoring-kube-prometheus-prometheus-1 3/3 Running 0 107s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 108s
service/monitoring-grafana ClusterIP 10.100.159.128 <none> 80/TCP 110s
service/monitoring-kube-prometheus-alertmanager NodePort 10.100.161.229 <none> 9093:30903/TCP,8080:30949/TCP 110s
service/monitoring-kube-prometheus-operator ClusterIP 10.100.182.102 <none> 443/TCP 110s
service/monitoring-kube-prometheus-prometheus NodePort 10.100.234.54 <none> 9090:30090/TCP,8080:31177/TCP 110s
service/monitoring-kube-state-metrics ClusterIP 10.100.167.66 <none> 8080/TCP 110s
service/monitoring-prometheus-node-exporter ClusterIP 10.100.110.32 <none> 9100/TCP 110s
service/prometheus-operated ClusterIP None <none> 9090/TCP,10901/TCP 108s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/monitoring-prometheus-node-exporter 2 2 2 2 2 kubernetes.io/os=linux 110s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/monitoring-grafana 1/1 1 1 110s
deployment.apps/monitoring-kube-prometheus-operator 1/1 1 1 110s
deployment.apps/monitoring-kube-state-metrics 1/1 1 1 110s
NAME DESIRED CURRENT READY AGE
replicaset.apps/monitoring-grafana-7d7c695546 1 1 1 110s
replicaset.apps/monitoring-kube-prometheus-operator-6cd8f7b5cc 1 1 1 110s
replicaset.apps/monitoring-kube-state-metrics-585b45df98 1 1 1 110s
NAME READY AGE
statefulset.apps/alertmanager-monitoring-kube-prometheus-alertmanager 1/1 108s
statefulset.apps/prometheus-monitoring-kube-prometheus-prometheus 2/2 108s
Cài đặt các thành phần Thanos
Sử dụng manifest của kube-thanos
Thanos Store Gateway
kubectl apply -f thanos-store-statefulSet.yaml -f thanos-store-service.yaml -f thanos-store-serviceMonitor.yaml -f thanos-store-serviceAccount.yaml
Thanos Compactor
kubectl apply -f thanos-compact-statefulSet.yaml -f thanos-compact-serviceMonitor.yaml -f thanos-compact-serviceAccount.yaml -f thanos-compact-service.yaml
Thanos Querier
kubectl apply -f thanos-query-deployment.yaml -f thanos-query-service.yaml -f thanos-query-serviceAccount.yaml -f thanos-query-serviceMonitor.yaml
<http://thanos-query.monitoring.svc.cluster.local:9090>
helm upgrade --install monitoring prometheus-community/kube-prometheus-stack \\
--namespace monitoring \\
--values values.yaml \\
--values values-config-prometheus.yaml \\
--version "60.2.0"
aws ec2 describe-subnets \\
--filters "Name=vpc-id,Values=vpc-0e37cde9d68625277" \\
--query "Subnets[*].{ID:SubnetId,AZ:AvailabilityZone,Name:Tags[?Key=='Name']|[0].Value}" \\
--output table
eksctl get nodegroup --cluster eks-fis-lab
eksctl create nodegroup \\
--cluster eks-fis-lab \\
--name worker-nodess \\
--node-type t2.large \\
--nodes 2 \\
--nodes-min 2 \\
--nodes-max 4 \\
--node-volume-size 30 \\
--managed
eksctl delete nodegroup --cluster eks-fis-lab --name worker-nodes
kubectl exec -it grafana-d7f7f4b7c-tf58l -n grafana -- cat /etc/grafana/grafana.ini | grep -A 10 '\\[smtp\\]'